![]()


Egy nehéz nap után a CFO fáradtan tért nyugovóra. Álmában megjelent kollégája, a CIO, aki élénken ecsetelte, hogy az adattárházak ideje lejárt. Ma, a big data korában a fejlett elemzések támogatására adattó kiépítésére van szükség. A CFO verejtékezve riadt fel álmából, de egy időre még a hatása alatt maradt. Homályosan felderengett előtte egy közelmúltban olvasott Gartner jelentés, de aztán újra álomba merült.

Idén a Gartner 300 pénzügyi vezetőtől kapott választ a világ minden tájáról és az összes főbb iparágból. A résztvevők 58 százaléka CFO volt. Az eredmények azt mutatták, hogy a pénzügyi vezetők mindenekelőtt a digitalizációra és alaptevékenységeik eredményeire koncentrálnak. Ennek fényében a pénzügyi vezetők idejük és erőfeszítéseik nagy részét várhatóan a fejlett adatelemzésre fordítják ebben az évben.
A legfontosabb megállapítások:
Vajon milyen folyamatok vezettek ahhoz, hogy most, mikor az adattárház technológiát végre érettnek tekinthetjük, máris új hívószóként bukkan fel az adattó kifejezés?
Az adatközpontú döntéshozatal megváltoztatja nemcsak a mindennapi munkavégzés, hanem egész életvitelünk módját. Az adattudománytól, a gépi tanulástól és a fejlett elemzésektől a valós idejű irányítópultokig a döntéshozók adatokat követelnek döntéseik meghozatalához. A pénzügyi szolgáltató szervezetek és a biztosítótársaságok mindig is adatközpontúak voltak, vegyük csupán az automatizált kereskedelem példáját. Az Internet of Things (IoT) megváltoztatja a gyártást, a közlekedést, a mezőgazdaságot és az egészségügyet. A mesterséges intelligencia és a gépi tanulás áthatja életünk minden aspektusát. A világ egyidejűleg állít elő és fogyaszt elképzelhetetlen mennyiségű adatot. A komplexiást azonban nem csupán az adatok mennyisége, hanem azok változatossága és sebessége is fokozza. Erre a jelenségre használjuk a ma már közismert „big data” kifejezést.
Ekkora mennyiség, változatosság és sebesség mellett a régi rendszerek és folyamatok már nem képesek kielégíteni a vállalat minden adatigényét.
E törekvések támogatása és a kihívások kezelése érdekében minőségi változás zajlik az adatkezelésben az adatok tárolásának, feldolgozásának és a döntéshozók számára történő prezentálásának területén. A big data technológia lehetővé teszi a méretezhetőséget és a költséghatékonyságot nagyságrendekkel nagyobb mértékben, mint ami a hagyományos adatkezelési infrastruktúrával lehetséges. Az önkiszolgálás átveszi a múlt gondosan kidolgozott és munkaigényes megközelítését, amikor az informatikai szakemberek jól megépített adattárházakat és adatpiacokat hoztak létre, de hónapokba telt bármilyen változtatás.
Az adattó egy merőben új megközelítés, amely kiaknázza a big data technológia erejét, és összeházasítja azt az önkiszolgálás rugalmasságával.
Mint láttuk, a döntéshozók nagy mennyiségű, változatos vagy éppen nagy sebességgel beérkező adatokat igényelnek döntéseik meghozatalához. Ezeknek az adatoknak „otthonra”, azaz célszerűen kialakított tárolóhelyre van szükségük. Ez a tárolóhely kapta az adattó elnevezést. A kifejezést James Dixon, a Pentaho vezérigazgatója alkotta meg és írta le először a blogjában: „Ha úgy gondolunk egy adatpiacra, mint a palackozott víz tárolójára – tisztított, csomagolt és strukturált a könnyű fogyaszthatóság érdekében -, akkor az adattó (data lake) nem más, mint egy nagy mennyiségű, természetes állapotában lévő víztömeg. Ez a tó sok különböző természetű forrásból töltődik fel, különféle felhasználók vizsgálhatják a tartalmát, elmerülhetnek benne, vagy mintát vehetnek belőle.” (2010)
2010 óta a fogalom jelentését a felhalmozódott tapasztalatok alapján többen is pontosították. Konszenzus látszik kialakulni a tekintetben is, hogy valóban költséghatékony módon az adattó felhő alapokon építhető ki.
A Forrester Now Tech: Cloud Data Lake, Q4 2020 című jelentésében a felhő alapú adattó fogalmát a következőképpen határozza meg:
„Az adattó olyan adattár, amely bármilyen adatot eltárol, feldolgoz, átalakít, biztonságossá tesz és hozzáférést is biztosít hozzájuk. Ezen adatok lehetnek strukturált, félig strukturált vagy strukturálatlan formátumban, valamint nyers, ill. gazdagított/finomított állapotban. Ily módon az adattó támogatni képes az adatfeltárást, az adatok előkészítését, a keresést, az adatvédelmet, az adattudományt és a fejlett elemzéseket.”
Mindez rendben is lenne így, de mi jellemzi az adattó és a hagyományos, relációs adattárház viszonyát? Kiszorítja-e az újabb a régit? Vagy inkább kiegészítik egymást? Egyáltalán miben különbözik az adattárház és az adattó?
A két megközelítés összehasonlítható maguk az adatok, az adatok feldolgozási sajátosságai, az agilitás foka, valamint a felhasználói közösségek jellemzői alapján:
A fentiek alapján levonható az a következtetés, hogy az adattó és az adattárház egymást kiegészítő technológiák. A magasan képzett elemző vagy adattudós által végzett gyors, feltáró elemzéshez az adattó a megfelelő választás. A megtisztított, minőségi és megbízható adatokon alapuló riportok nagyszámú felhasználóhoz történő eljuttatásához az adattárház a továbbiakban sem nélkülözhető. Más szavakkal: soha ne intézzünk olyan kérdést egy adattó felé, hogy pontosan hány százalékban sikerült teljesíteni az előző negyedévi megrendeléseket. Erre szolgál az adattárház. Cserébe soha ne forduljunk egy adattárházhoz azzal a kérdéssel, hogy hozzávetőlegesen ügyfeleink mekkora hányada táplál irántunk negatív érzelmeket azóta, hogy a múlt heti rendszerkimaradás miatt nem teljesítettük online rendeléseiket. Erre való az adattó, mely ügyfeleink összes olyan rezdülését tartalmazza (szóbeli vagy írásbeli hozzászólás, kép vagy videó formájában), melyeket sikerült begyűjtenünk.
A fentebb hivatkozott Forrester jelentés a felhő alapú adattó megoldások piacának elemzését két tényezőre alapozta: a piaci jelenlétre és a funkcionalitásra.
A piaci jelenlét elemzése során a vizsgált piacon található szállítókat három kategóriába sorolták, a felhő alapú adattó megoldásaik értékesítéséből származó éves bevételeik alapján: nagy játékosok (több mint 500 millió dolláros éves bevétel), közepes méretű játékosok (100 millió és 500 millió dollár közötti) és kisebb szereplők (kevesebb, mint 100 millió dollár). Nem vették figyelembe azokat a szállítókat, amelyek becsléseik szerint 1 millió dollárnál kevesebb éves bevételt realizáltak a kategóriában. A három kategóriába tartozó piaci szereplőket az alábbi ábra illusztrálja.
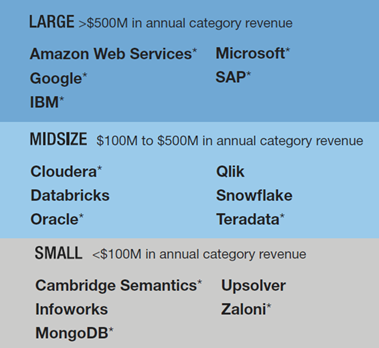
Ez alapján a Forrester az alábbiak szerint kategorizálta a a jelentős piaci szereplőket:
Ha a CFO arra gondol, hogy SAP rendszere okán eddig BW-je volt akkor íme az adattó kínálata a német szoftver óriásnak
Az SAP 2020 áprilisában jelentette be a HDL-t (HANA Data Lake). Ez része az SAP HANA felhő szolgáltatásoknak (SAP HANA Cloud Services). Az SAP HANA Cloud Services olcsó tárolási lehetőségeket kínál, beleértve az SAP HANA tárolókiterjesztést és a beépített adattavat.
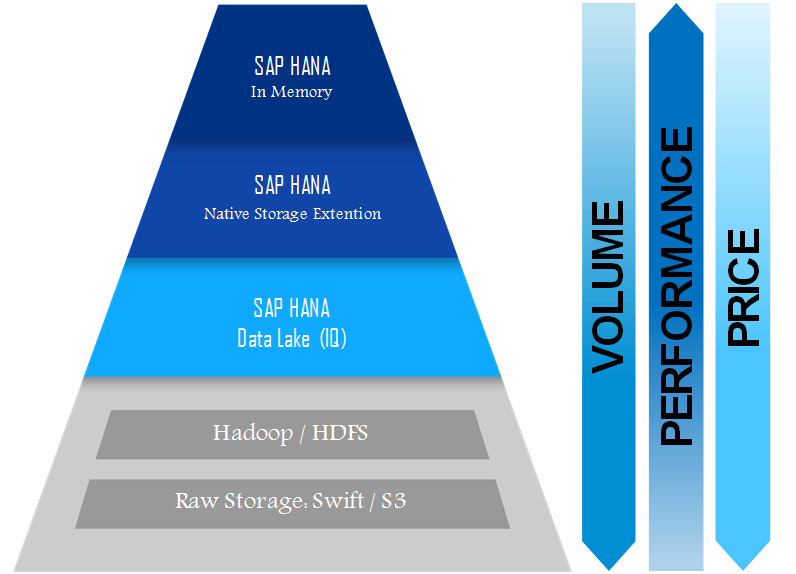
Az ügyfelek az aktuális, üzleti szempontból kritikus (forró) adatokat a memóriában tárolhatják a valós idejű feldolgozáshoz, és a gyakran, de nem mindennap használt (meleg) adatokat az SAP HANA Native Storage Extension (NSE)-be helyezhetik át. A régebbi, de még mindig fontos (hideg) adatok esetén az ügyfelek használhatják a HANA Data Lake-t (IQ), és továbbra is megtarthatják az adatokhoz való hozzáférés lehetőségét, amikor és ahol szükségük van rá. Ez az adatréteg segít csökkenteni a költségeket, és szabadságot ad arra nézve, hogy megválassza, hol tárolja adatait attól függően, hogy mikor van szüksége azokra.
A HDL kiváló tömörítést kínál. A meglévő adatok tízszeres tömörítése komoly tárolási költségmegtakarítást eredményez. Strukturált és strukturálatlan adatokat is képes tárolni. A HDL-ben bármikor bővíthető a tárhely, emellett rendelkezik a HANA felhőbiztonságával is. Olyan szolgáltatásokat nyújt, mint az adatok titkosítása, naplózás és az adatokhoz való hozzáférés nyomon követése.
A CFO reggel kipihenten ébredt, nem is emlékezett semmire. De munkába menet a piros lámpánál várakozva arra gondolt, hogy ma tüzetesebben is elolvas egy bizonyos Gartner jelentést. Ha pedig legközelebb összefut a CIO-val a büfében, meghívja egy kávéra.
A szerző senior expert, IFUA
Olvasson tovább a témáról az IFUA Horváth honlapján!
Szakértőink vállalati projektekben szerzett tapasztalatait és ügyfeleink elismeréseit egyaránt megosztjuk.




