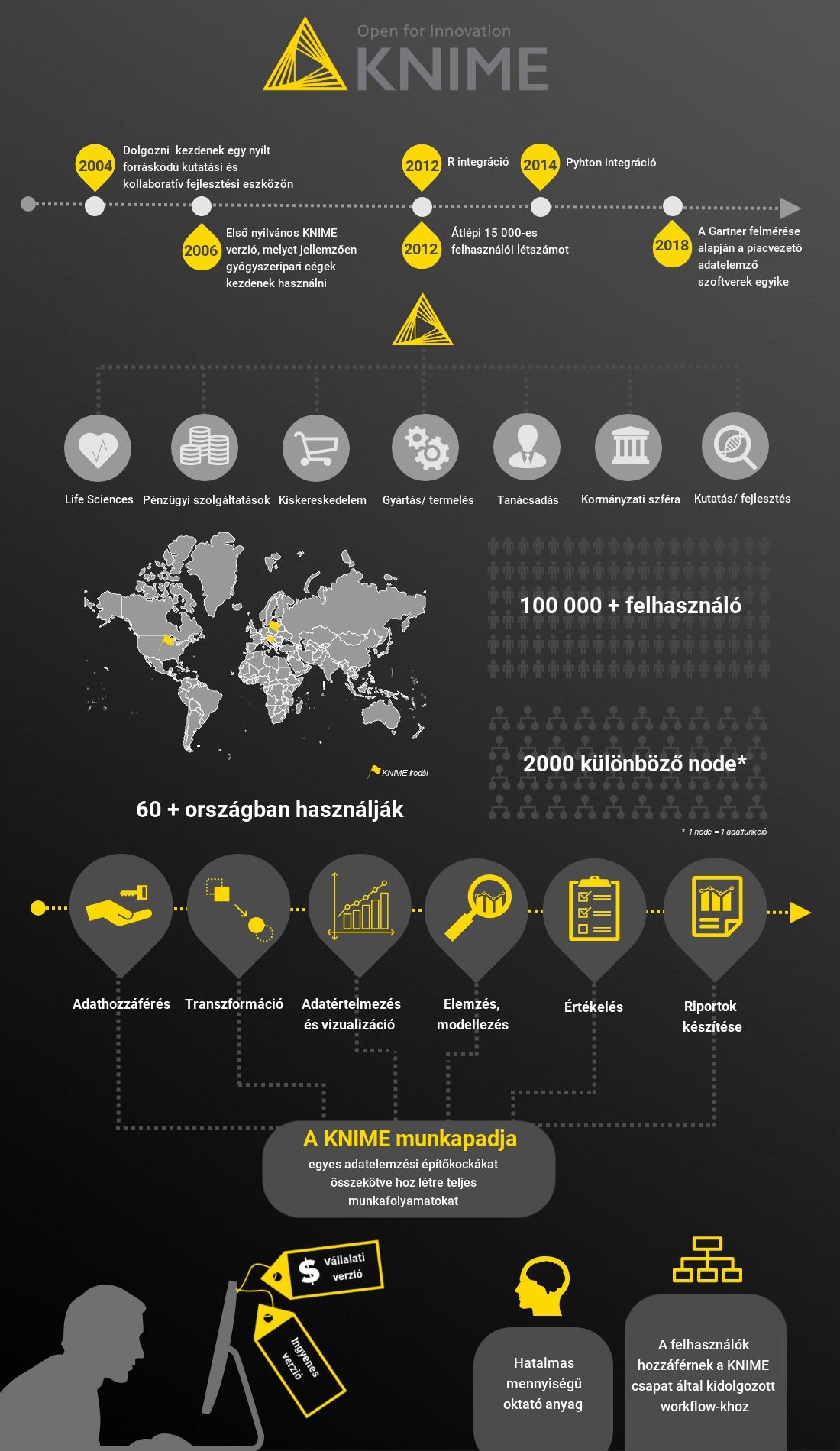
![]()

Ezen platformok használata a programozási ismeretekkel nem feltétlenül rendelkező felhasználó/adatelemző számára is lehetővé teszi, hogy ún. építőkövekből (node-okból ~ egy elemzési funkció) tetszőleges nagyságú és felhasználói igény szerinti komplexitású munkafolyamatot (workflow) állítson össze.
A munkafolyamatok kialakításával kezelhetővé, könnyen és gyorsan elemezhetővé válnak a legkülönbözőbb adatforrások. Fontos, hogy ezek az eszközök kifejezetten az adatok mögött rejlő mintázatok azonosításában erősek, ami által az adatok mögött meghúzódó információ kiaknázhatóvá válik, ezáltal érdemben támogatva az üzleti döntéseket.
Adatbányászati eszközökkel oldhatók meg többek között az olyan típusú feladatok, mint a vevők szegmentálása a differenciált ügyfélkiszolgálás érdekében, a hiteligénylők klasszifikálása a jobb hitelbírálat érdekében vagy épp az értékesítés előrejelzése a működőtőke optimalizálása érdekében. Ezek olyan elemzések, amelyek már „kinövik” az Excel adta lehetőségeket, túlmutatnak azon.
A szoftverfejlesztő vállalatok mára számos ún. „önkiszolgáló” predikciós eszközt kifejlesztettek, ma már itt is inkább a bőség zavara okozza a problémát.
A Gartner legutóbbi (2019. január) felmérése alapján az alábbi (nem open-source) adatbányász eszközök kerültek be a Magic Quadrant-ba:
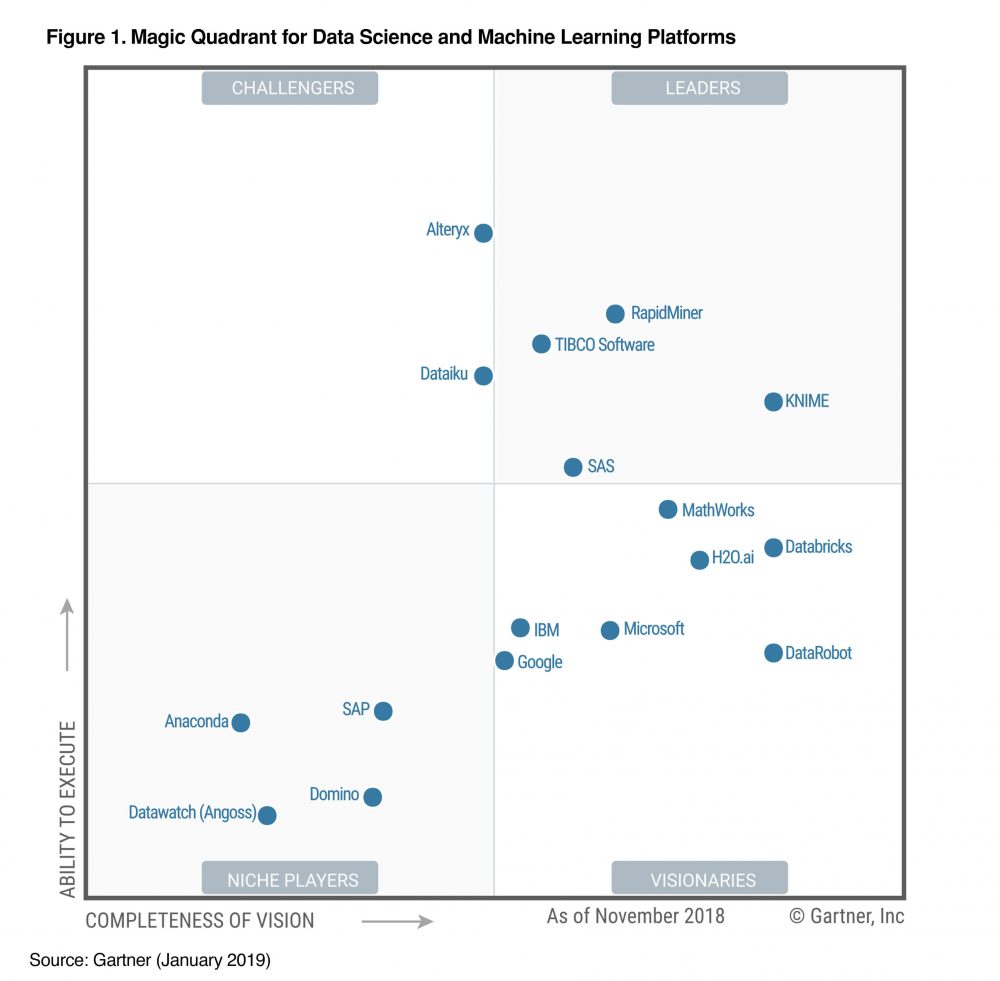
A Gartner Magic Quadrant két szempont szerint, kvalitatív módszerekkel értékeli a szoftverszállítókat:[3]
A két szempont szerint négy kategóriát különít el a Gartner: 1) vezetők (leaders), 2) kihívók (challengers), 3) piaci rész szereplők (niche players), 4) vizionálók (visionaries). A 2x2-es mátrix jobb felső sarkában vannak azok a szereplők, akik mind jövőkép, mind pedig végrehajtási képesség szempontjából jelenleg a legérdekesebbek, legjobbak a piacon a Gartner értékelése alapján.
A klasszikus BI megoldásokat szállító nagy cégek (IBM, SAS, Microsoft) mellett a TIBCO, RapidMiner[4] és a KNIME az, amelyeket a Gartner elemzése alapján érdemes kiemelni. Ezek közül is kitűnik a KNIME, amely bár a Leader kategória legfiatalabb tagja[5], már az előző években is a jobb felső sarokban „lakott”, azonban 2019-re abszolút kategóriagyőztessé vált.
A továbbiakban egy lehetséges felhasználási példát mutatunk be a fiatal KNIME-mal, amely ideális választás lehet az adatbányászat iránt érdeklődő, programozási tudással nem rendelkező kezdők számára is. Az alapszoftver (KNIME Analytics Platform) mindenki számára ingyenesen letölthető és korlátozásmentesen (sem időbeli, sem funkcionális, sem adatméretbeli korlátok) használható egy rövid regisztrációt követően[6]. Az elemzési logika alapvetően platformfüggetlen, jellemzően a többi eszközben is megvalósítható.
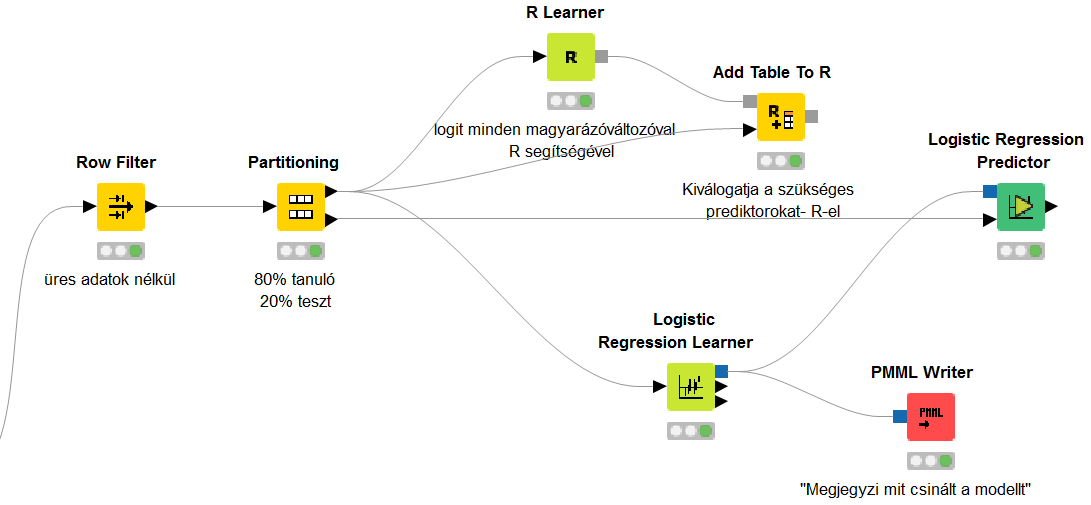
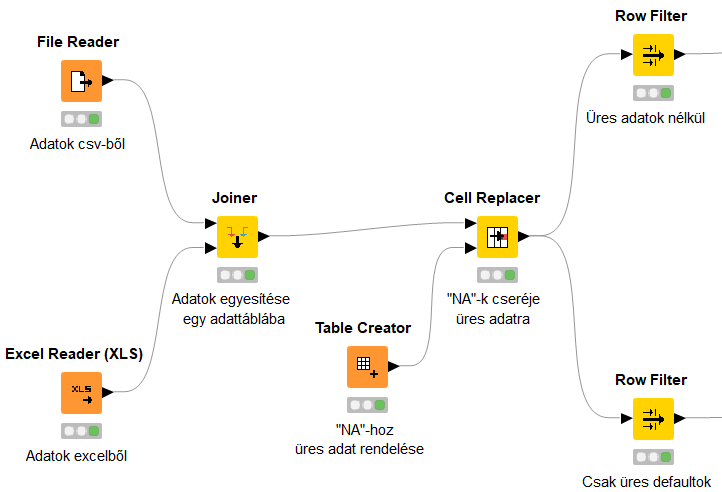
Első lépésként egy File Reader és egy Excel Reader node segítségével a két forrásból betöltjük az adatainkat KNIME-ba. Azonban mivel egy adattáblában szeretnénk látni az adatokat, a Joiner node használatával összekötjük a két táblát. Esetünkben – az egyszerűség kedvéért - a két fájlban ugyanolyan sorrendben szerepelnek az ügyfelekhez tartozó adatok, így a Joiner node a sorszám alapján feleltette meg őket egymásnak. Adott esetben lehetőség van más típusú összekötésre is.
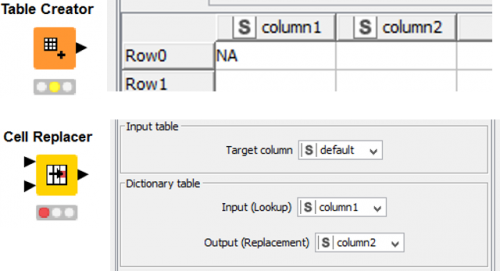
Az adatok betöltése után a 150 hiányzó/üres „default” ügyféladatot a KNIME nem üres adatként értelmezi, hanem „NA” -ként, emiatt a default változónak három lehetséges értéket tulajdonít (Yes/No/NA). Annak érdekében, hogy az NA-kat hiányzó/üres adatként értelmezze (ekkor tudunk rá predikciót készíteni), a Table Creator node-dal készítünk egy 1x2-es táblát, aminek első oszlopába NA-t írunk, a másodikba pedig semmit (üres adat) majd a Cell Replacer Node-dal a default oszlop minden olyan adatát, amely megfelel az 1x2-es táblázatunk első cellájának (NA) kicserélünk a másodikra (üres adat).
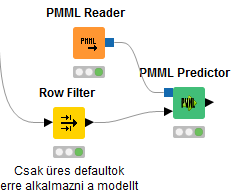
A következő lépésben a Row Filter node segítségével szétszedjük az adattáblát két részre az ügyfelek mentén vágva: egy 700 soros részre, amelyen a modellt építjük, valamint egy 150 soros részre, amelyen ezt követően a modellt alkalmazzuk.
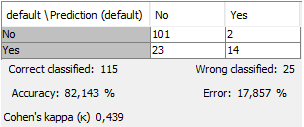
A modellépítéshez a 700 sorunkat is két részre szedjük a Partitioning node-dal, az ügyfelek 80%-át használjuk a logit regresszió tanításához (Train Set), a maradék 20%-án (Test Set) pedig teszteljük a modellt. Továbbá beállítjuk, hogy a két részben (Train és Test Set) a default aránya hasonló legyen, valamint a reprodukálhatóság érdekében beállítunk egy random seed-et is. A modell a tanuló idősoron tanul (arra optimalizálja az illeszkedést), majd egy ettől független teszt idősoron kerül visszamérésre a modell várható pontossága. A Test adatokon visszamért pontosság alapján képet kapunk arról, hogy a modellünk mennyire pontosan jelez előre nem hozzáférhető adatokon. Ebből következtethetünk arra is, hogy mennyire lesz pontos a modell az új adaton (esetünkben 150 bejövő ügyfél adatán).
Most következne a logisztikus regresszió, azonban ahhoz tudnunk kellene, hogy milyen változókat (prediktorokat) használjunk. A KNIME-ban nincs olyan node, amely kiválasztaná, hogy mely magyarázó változókra van szükségünk. Lehetséges azonban a KNIME-ban R kód futtatása is, így most ezt használva egy iteratív eljárást alkalmazunk ahhoz, hogy megtaláljuk, mely változók beépítésével kapjuk a legjobb modellt. Miután meggyőződtünk arról, hogy az R bővítmények hozzá vannak adva a KNIME-hoz (file-install KNIME extensions), az R Learner és az Add Table To R node-okat használjuk. Az R kiterjesztésnél a kódban az adattáblánkra knime.in néven kell hivatkozni.
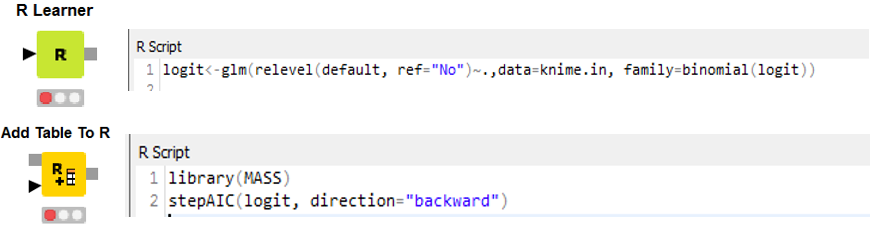
Kimenetelként egy ugyanolyan R Workspace képet kapunk, mint amilyet az R-ben is kapnánk. A modellszelekciós algoritmus alapján az age, debtinc, address, creddebt és employ változókat érdemes felhasználnunk modellünkben.
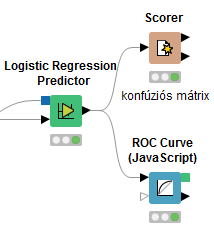
A kiválasztott változókat megadjuk a Logistic Regression Lerner node-ban, ezt követően pedig a Logistic Regression Predictor node az adattáblánkhoz hozzáadja új oszlopként a becsléseket (figyeljünk, hogy ezt már a „20%-os” teszt adatokkal kössük össze). Végül a modellt elmentjük a PMML Writer node-dal, hogy azt majd a 150 bejövő ügyfélre (és a későbbi „új” ügyfelekre) alkalmazhassuk.