![]()


A Machine Learning technológiák terjedése minden olyan iparágat és területet érint, ahol sok az adat. És hol nincs 2018-ban sok adat? Cikkünkben összefoglaljuk, hogy a HR területen hogyan tud segíteni a gépi tanulás.

Ahogy említettem, minden az adatokkal kezdődik. A ma elérhető vállalati adatok múltbeli adatok. Az ezeket megjelenítő összehasonlító- vagy idősoros jelentések mind múltbeli eseményeket dolgoznak fel. Idősor esetén az emberi szem képes „extrapolálni”, folytatni a görbét. Egyszerűbb idősoroknál az emberi agy egy pillantás alatt rájön, hogy mi a lényeg. Az adott görbe felfelé- vagy lefelé fog folytatódni, vagy az a lényeg, hogy két héttel ezelőtt volt egy nagy ugrás a grafikonban.
De az alábbi idősor esetén már egyáltalán nem olyan könnyű megmondani, hogyan fog folytatódni:
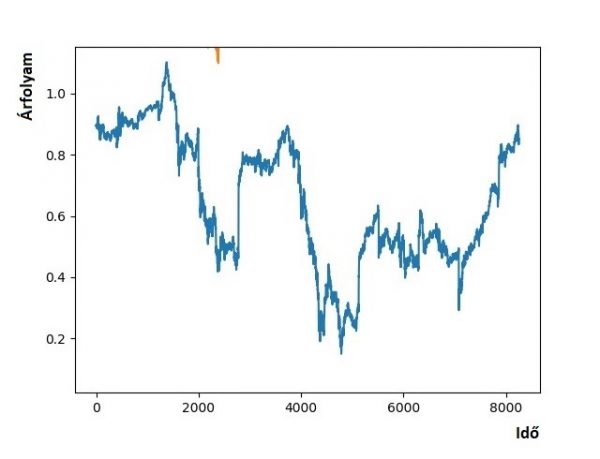
A múltbeli adatok kiegészítése a jelen adataival már jóval komplexebb feladat, hiszen ekkor valós idejű adatfeldolgozásra van szükség. Ebben az esetben már lehetőség van élő dashboard-ra is. Sőt, szabályok (Ha itt ez történik, akkor ott az legyen!) és adott feltételek bekövetkezése esetén kiadott riasztások is alkalmazhatók.
Például kapjak egy értesítést,
Az emberiséget mindig is a jövő érdekelte a legjobban. De ki tud a jövőbe látni? Az, aki teljes mértékben átlátja, megismerte a múlt és a jelen működését. De ki tud átlátni milliónyi folyamatot, változót, paramétert? Hát a Machine Learning. Neki ma már majdhogynem teljesen mindegy, hogy mennyi adattal kell dolgoznia. Egy modell, amelyet a múlt és a jelen adatai alapján tanítottunk be, az élő adatokat is figyelembe véve igen nagy százalékban képes megjósolni a jövőbeli eseményeket.
Most már csak az a kérdés, hogy mit értünk „igen nagy százalékban” alatt 🙂 . Nos, a választott algoritmustól, tanító adatoktól függően 90% feletti, nem ritka esetben 98% körüli eredmény is elérhető, de azt tudni kell, hogy minél távolabbi jövőben bekövetkező változásokat szeretnénk megjósolni, annál kisebb a becslés pontossága.
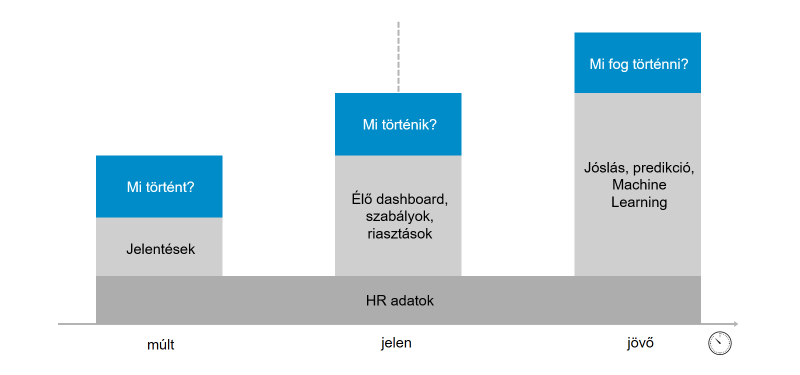
Mit kezdhetünk a múltban, jelenben és a jövőben keletkező adatokkal?
A Machine Learning a mesterséges intelligencia egy fajtája. Mivel mostanában nagyon sokat foglalkoznak vele, könnyen azt gondolhatjuk, hogy ez valami új dolog, pedig jóval idősebb, mint én. Célja, hogy egy tanulási fázist követően képes legyen feladatokat elvégezni, anélkül, hogy – a hagyományos számítógépes rendszerekkel ellentétben – erre külön be kéne programozni.
Ez azt jelenti, hogy Machine Learning alkalmazása esetén nem kell előre ismerni a bemenő adatok és a végeredmény közötti összefüggést. A Machine Learning tehát az első ember által előállított dolog, amely pusztán a tanításra szánt minták alapján képes megtanulni, hogy mit kell tennie. Épp úgy, mint ahogy a gyerekek is teszik: nézik, kipróbálják, ellenőrzik, újra próbálják egészen addig, amíg elég jól meg nem tanulják, bármiről is legyen szó.
Fontos megemlíteni, hogy a modell betanításához rengeteg tanító adatra van szükség. Ezért Machine Learning alapú megoldások leginkább a jól ismert, sok adatot kezelő cégektől várhatók[1].
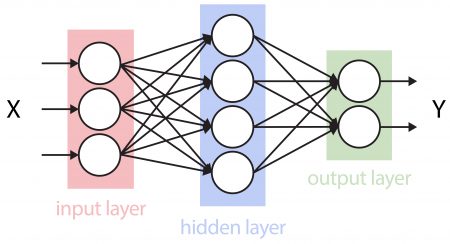
Machine Learning: A feladatot leíró folyamat és az azt implementáló program helyett egy feladattól független neurális hálózat működik.
A Machine Learningnek két fő fajtáját különböztetjük meg: a Supervised és az Unsupervised Learning-et. Előbbi esetben előre tudjuk, hogy milyen tanító mintákra milyen eredményt várunk, az utóbbinál pedig nem.
Kicsit olyan a különbség, mint amikor valaki egy nyelvtanárral tanul egy idegen nyelvet vagy csak úgy, az adott országban, egymagában. Előbbi esetben a tanár többnyire elmondja, leírja, hogy mi mit jelent, míg egy idegen környezetben fogalmunk sincs, mit beszélnek hozzánk. A tudást menet közben kell felszednünk.
Két fő fajtája van ( több nem lesz 🙂 ):
Regressziót akkor alkalmazunk, ha a kimenő érték sok értéket vehet fel, nem csak bizonyos kategóriákat jelez. Ilyen lehet például a jövedelem, az életkor vagy az adott kolléga vezetői alkalmassága egy 100-as skálán. Az alábbi példában egy égési folyamat során a hőmérsékletet mutatjuk az ózonkoncentráció függvényében.
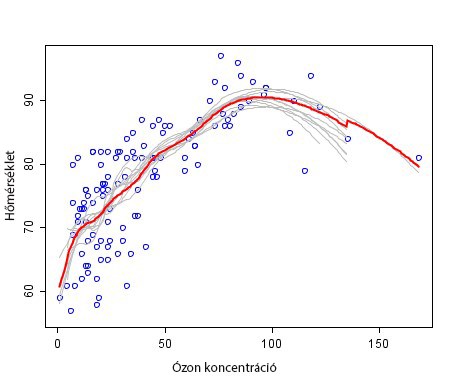
Supervised Learning – Regresszió
Mire használhatja a HR a regressziós algoritmusokat?
Osztályozás esetén a kimenő értékek véges számú értéket vehetnek fel, tehát a bemenő mintákat valójában a kimenő értékek, mint címkék alapján osztályozzuk. Ilyen lehet például az, hogy valaki milyen fizetési kategóriában van (fontos: szándékosan nem fizetést írtunk, hanem a kisszámú fizetés kategóriát!), vagy életkor sávokban (pl. fiatal/középkorú/idős), a kolléga neme (nő/férfi) vagy az, hogy az illető az algoritmus szerint fel fog-e mondani a következő 1 évben (igen/nem).
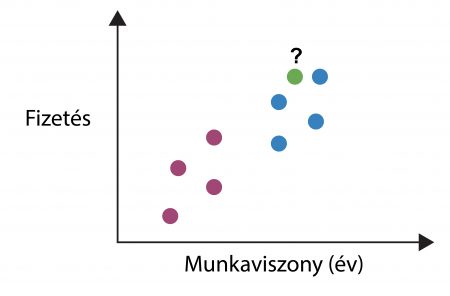
Supervised Learning – Osztályozás
Példák osztályozásra:
Ide sorolhatjuk azokat a problémákat, amikor a bemenő adatokat úgy szeretnénk osztályozni, hogy nem tudjuk előre a kategóriákat. Ilyenkor épp az lehet a feladat, hogy az osztályokat meghatározzuk. Ezt a folyamatot más néven szegmentálásnak is hívjuk.
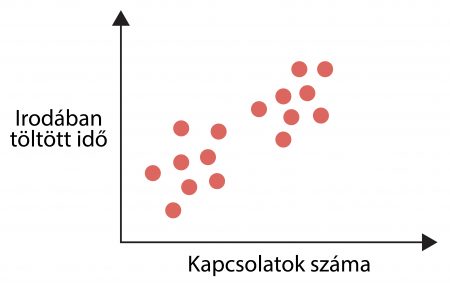
Unsupervised Learning – Szegmentálás
Tipikus szegmentálási feladatok:
A Machine Learning az emberiség történetében az első olyan gépi segítség, amely úgy képes megválaszolni kérdéseket, hogy nem kell előtte az embernek kitalálnia azt a folyamatot, amely mentén már kikövetkeztethető a válasz. A Machine Learninggel tipikusan optimalizálási, osztályozási vagy szegmentálási feladatokat végeztethetünk.
A Machine Learninghez sok tanító adat kell, ezért hosszú időre visszamenő adatsorra vagy hazánknál sokkal nagyobb adatforrásra van szükség. Ha a modell már be van tanítva, akkor egy kisvállalat is élvezheti az előnyeit.
De ne éljünk mindig a számok bűvöletében! Néha nézzünk rá az adatsorokra szabad szemmel is. Az alábbi adathalmazok szinte minden statisztikai mutatója 2 tizedesjegyig megegyezik, mégis nagyon eltérnek egymástól. Ez is jelzi, hogy felelős döntéseknél az emberre még egy jó ideig szükség lesz.

Datasaurus – Ezek halmazok 2 tizedesjegyig azonos statisztikai mutatókat eredményeznek. Forrás: http://blog.revolutionanalytics.com/2017/05/the-datasaurus-dozen.html
A szerző az IFUA Horváth & Partners analitikai szolgáltatásokért felelős vezetője
[1] Nem véletlen, hogy a Workday a napokban jelentette be két Machine Learninggel foglalkozó cég – Rallyteam és Adaptive Insights – felvásárlását is.




